RAG 통합검색
Ctrl+K를 누르면 워크스페이스의 모든 작업 흔적이 하나의 검색창에 모입니다. 단어가 정확히 일치하지 않아도 의미로 찾아내며, 임베딩은 전부 로컬에서 계산되므로 코드가 외부로 나가지 않습니다.
6개 검색 소스
섹션 제목: “6개 검색 소스”| 소스 | 인덱싱 대상 | 예시 질문 |
|---|---|---|
code | 텍스트·코드 파일 (40개 이상 확장자) | “비밀번호 저장하는 함수” |
db | 테이블·뷰·인덱스·트리거·루틴 정의 | ”주문 금액 합산 뷰” |
git | 커밋 메시지·diff | ”지난주 인코딩 버그 수정 커밋” |
chat | AI 채팅 대화 내용 | ”어제 AI한테 물어본 배포 방법” |
work_event | 패널 활동 기록 (열기·편집·쿼리 실행 등) | “최근에 열었던 마이그레이션 파일” |
doc | 마크다운·문서 파일 | ”API 인증 절차 문서” |
코드만이 아니라 “지난주에 그 테이블 어떻게 고쳤더라?” 같은 작업 맥락까지 검색됩니다.
하이브리드 검색 엔진
섹션 제목: “하이브리드 검색 엔진”하나의 질의가 두 갈래로 동시에 실행됩니다.
- 벡터 검색 — sqlite-vec KNN. 의미가 비슷하면 단어가 달라도 찾습니다.
- 키워드 검색 — FTS5 BM25. 정확한 식별자·에러 메시지에 강합니다.
두 결과를 RRF(Reciprocal Rank Fusion)로 융합해 최종 순위를 매깁니다. 한쪽 방식이 놓친 결과를 다른 쪽이 보완하므로 단독 방식보다 일관되게 좋은 결과를 얻습니다. deprecated / legacy / .bak 경로는 자동으로 감점 처리됩니다.
리랭킹 (옵트인)
섹션 제목: “리랭킹 (옵트인)”검색 품질을 더 끌어올리고 싶다면 리랭커를 켤 수 있습니다.
- 상위 후보 40개를 cross-encoder 모델(
bge-reranker-base, 한국어 포함 다국어)이 질의와 1:1로 대조해 재정렬합니다. - 최신성 가중치 — 최근 30일 결과에 가산점, 1년 이상 오래된 청크는 감쇠합니다.
- 인용 횟수 가중치 — AI 답변에 실제 인용된 횟수가 높을수록 상위에 오릅니다.
코드를 아는 청킹
섹션 제목: “코드를 아는 청킹”코드 파일은 단순히 N줄씩 자르지 않습니다. tree-sitter AST 파싱으로 함수·클래스·메서드 경계에서 청크를 나눠(기본 6 KB), 검색 결과가 “함수의 반 토막”이 아니라 온전한 의미 단위로 나옵니다.
| 지원 언어 | 청킹 방식 |
|---|---|
| Python · JavaScript · TypeScript · TSX | tree-sitter AST |
| C# · Java · Go · Dart | tree-sitter AST |
| 그 외 언어 · 초대형 파일 | 줄 단위 안전 폴백 |
로컬 임베딩 모델
섹션 제목: “로컬 임베딩 모델”임베딩 모델은 transformers.js 기반으로 앱 안에서 실행됩니다. API 키도, 네트워크 전송도 필요 없습니다. 첫 사용 시 모델을 한 번만 내려받고 이후에는 오프라인에서도 동작합니다.
| 모델 | 차원 | 크기 | 비고 |
|---|---|---|---|
multilingual-e5-small | 384 | 약 110 MB | 기본값, 빠름 |
multilingual-e5-base | 768 | 약 280 MB | 한국어 권장 — 검색 품질이 눈에 띄게 향상됩니다 |
| MiniLM · bge 계열 | 384 | 90~130 MB | 영어 위주 프로젝트용 경량 |
embeddinggemma-300m | 768 | 약 600 MB | 베타 |
사용 방법
섹션 제목: “사용 방법”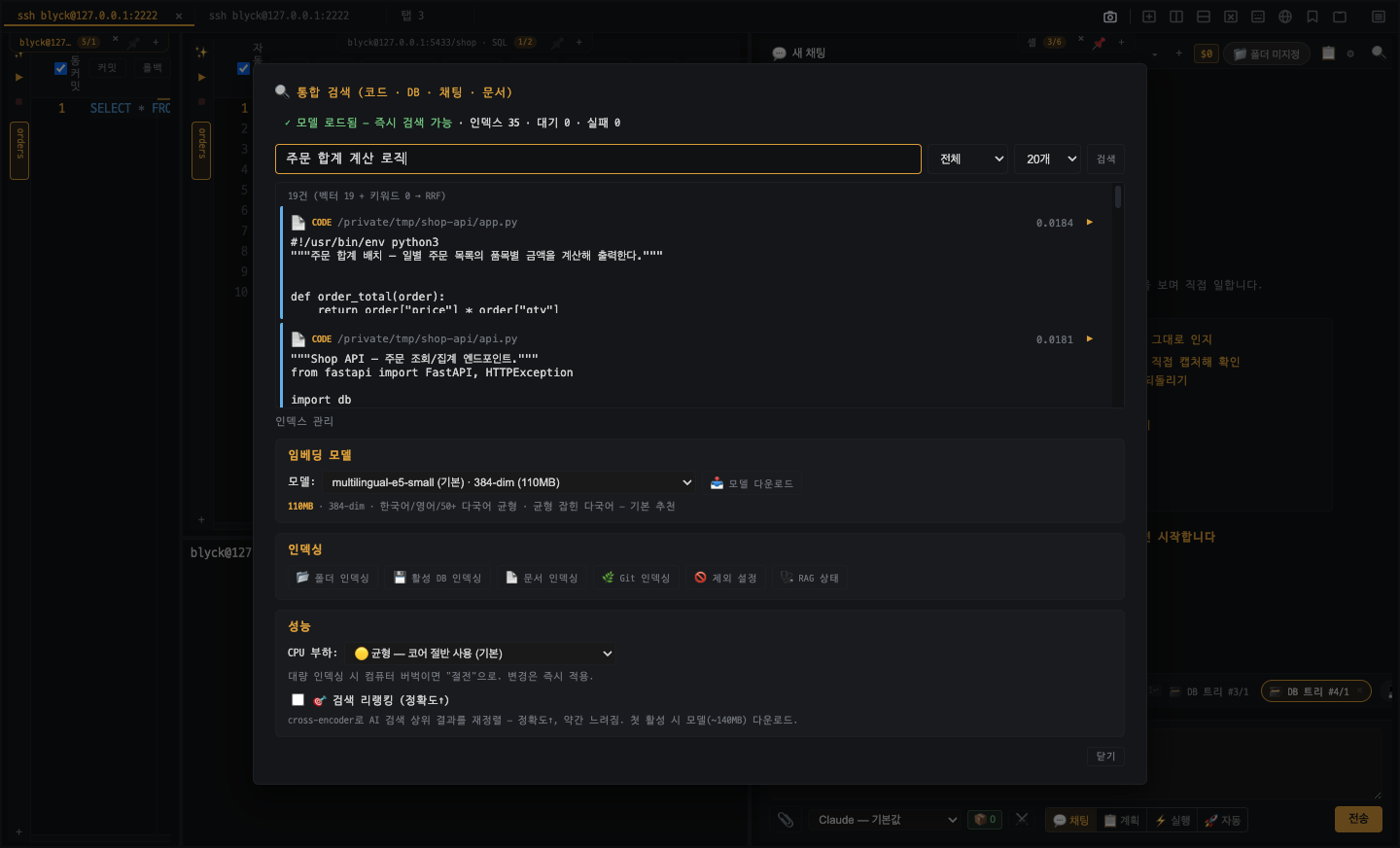
-
Ctrl+K를 눌러 통합 검색창을 엽니다. -
자연어로 입력합니다.
SSH 비밀번호 저장하는 부분지난주에 고친 인코딩 버그orders 테이블에 amount 컬럼 추가한 커밋 -
소스 필터 칩(code · db · git · chat · work_event · doc)으로 범위를 좁힙니다.
-
결과 카드를 클릭하면 내용이 펼쳐지고, ▶ 버튼을 누르면 원본 파일·위치로 이동합니다.
AI 채팅과의 자동 연동
섹션 제목: “AI 채팅과의 자동 연동”AI 채팅은 사용자가 메시지를 보내기 전에 workspace_search 도구로 인덱스를 자동 검색합니다. 관련 코드·과거 대화·DB 스키마를 컨텍스트로 가져와 답변의 정확도를 높입니다. 별도 조작이 필요 없으며, 인용된 파일은 답변 아래 “참고:” 섹션에 표시됩니다.
인덱싱 관리
섹션 제목: “인덱싱 관리”자동 인덱싱
섹션 제목: “자동 인덱싱”- 파일 저장 또는 DB 스키마 변경이 감지되면 백그라운드에서 증분 인덱싱됩니다.
- 모드 선택 — 채팅 설정에서
eco/balanced/fast중 선택해 CPU 사용량과 반영 속도의 균형을 조절합니다. - 상태 대시보드 — 채팅 설정 → RAG 인덱스 상태 탭에서 소스별 청크 수와 인덱싱 큐를 실시간으로 확인합니다.
제외 패턴
섹션 제목: “제외 패턴”.gitignore를 자동으로 존중하며, 아래 경로는 기본 제외됩니다.
node_modules/ .git/ dist/ build/추가 제외가 필요하다면 프로젝트 루트의 .termeditignore 파일에 적습니다(gitignore 문법). DB 객체는 [db] 섹션에 glob 패턴으로 제외합니다.
# .termeditignore 예시vendor/*.generated.tscoverage/
[db]*.tmp_*BACKUP_*패턴을 저장하면 이미 인덱싱된 해당 청크도 즉시 정리됩니다.
인덱스 청소 도구
섹션 제목: “인덱스 청소 도구”오래된 워크스페이스에서 인덱스가 비대해지면 대시보드의 청소 도구를 사용하세요.
| 도구 | 역할 |
|---|---|
| Orphan Scan | 삭제된 파일의 잔여 청크 제거 |
| Pattern Purge | 경로 패턴(예: dist/**)으로 일괄 제거 |
| Stale Cleanup | 오래 인용되지 않은 청크 정리 |
| 실패 재시도 | 인덱싱 실패 항목 재처리 |
인덱스 저장 위치 & 크기
섹션 제목: “인덱스 저장 위치 & 크기”인덱스는 워크스페이스별 SQLite 파일(workspace.sqlite)로 저장됩니다. 워크스페이스 폴더를 옮기면 새로 인덱싱됩니다.
크기는 부담 없는 수준입니다. 1만 청크 기준 벡터 데이터가 약 15 MB입니다.
FAQ
섹션 제목: “FAQ”검색창이 열리지 않아요
→ Ctrl+K를 사용합니다. 입력 포커스가 다른 단축키와 충돌하는 경우 빈 영역을 한 번 클릭한 뒤 다시 시도합니다.
결과가 없거나 이상해요
→ 첫 실행 직후에는 모델 로드·다운로드가 완료될 때까지 결과가 비어 있을 수 있습니다. 인덱싱 상태 대시보드에서 진행률을 확인하세요. 노이즈가 많다면 .termeditignore로 불필요한 경로를 제외하세요.
오래된 결과가 계속 나와요 → 인덱스 상태 탭 → Orphan Scan 또는 Stale Cleanup을 실행합니다. 모델을 변경한 직후라면 재인덱싱이 완료될 때까지 기다립니다.
임베딩 모델을 바꾸면 기존 인덱스는요? → 모델을 변경하면 기존 인덱스가 자동으로 삭제되고 처음부터 다시 인덱싱됩니다. 프로젝트 규모에 따라 수 분이 소요될 수 있습니다.
원격(SSH/SFTP) 폴더도 인덱싱되나요?
→ 아직 지원되지 않습니다. 원격 프로젝트 폴더에서는 RAG 코드 검색이 비활성화되며, AI가 file_list_dir + file_read 도구로 직접 탐색합니다.
AI 답변에 코드가 잘못 인용됩니다
→ 소스 필터를 조정하거나 .termeditignore로 노이즈 파일을 제외하면 인용 품질이 개선됩니다. 리랭킹 옵션을 켜면 관련성이 낮은 청크가 밀려납니다.